As machines scale up in number, benefits you had when using a single-instance running your softwares are lost, among which we find operating with shared resources in a mutually exclusive way. Alright, what's that in human words?
Well, think like you need to send an email to all customers every day: given you only have one server that is pretty easy to achieve even with a simple unix cronjob that runs at midnight every day. The problem is when you have more than one machine up and running in the wild and you do need to ensure such operation is only fired once per day. Suddenly you cannot use hard-coded per-machine logic like cronjobs!
We then would need a way to lock down (hold) further attempts to do such operation once the first one has started, meanwhile guaranteeing:
- 1. Mutual exclusion: at any given moment, only one client can hold a lock.
- 2. Deadlock free: eventually it is always possible to acquire a lock, even if the client that locked a resource crashes.
- 3. Fault tolerance: as long as the majority of machines (or nodes) are up, the software (aka client) should be able to acquire and release locks.
Fortunately enough, systems like Redis can help us dealing with this. Given a Redis client, we can use the following command to store a key when it does not exist:
 The command will set the key only if it does not already exist (NX option), with an expire of <timeout> milliseconds (PX option). The key is set to a value <uuid> (which is going to be a random value). This value must be unique across all clients and all lock requests.
The command will set the key only if it does not already exist (NX option), with an expire of <timeout> milliseconds (PX option). The key is set to a value <uuid> (which is going to be a random value). This value must be unique across all clients and all lock requests.
The random value is used in order to release the lock in a safe way, with a script that tells Redis: remove the key only if it exists and the value stored at the key is exactly the one I expect to be. This is accomplished by the following Lua script:
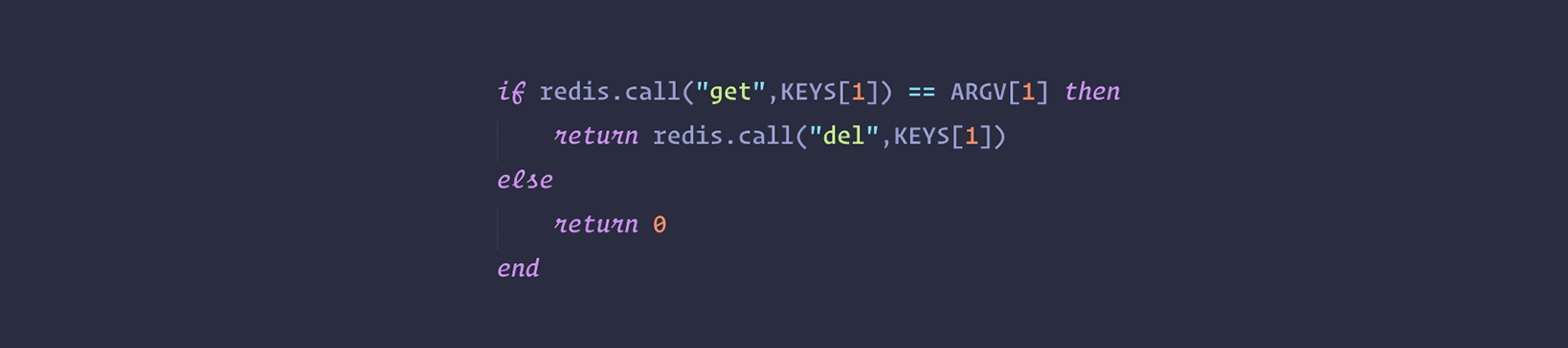 This is important in order to avoid removing a lock that was created by another client. For example a client may acquire the lock, get blocked in some operation for longer than the lock validity time (the time at which the key will expire), and later remove the lock, that was already acquired by some other client. Using just DEL is not safe as a client may remove the lock of another client. With the above script instead every lock is “signed” with a random string, so the lock will be removed only if it is still the one that was set by the client trying to remove it.
This is important in order to avoid removing a lock that was created by another client. For example a client may acquire the lock, get blocked in some operation for longer than the lock validity time (the time at which the key will expire), and later remove the lock, that was already acquired by some other client. Using just DEL is not safe as a client may remove the lock of another client. With the above script instead every lock is “signed” with a random string, so the lock will be removed only if it is still the one that was set by the client trying to remove it.
The time we use as the key time to live, is called the “lock validity time”. It is both the auto release time, and the time the client has in order to perform the operation required before another client may be able to acquire the lock again, without technically violating the mutual exclusion guarantee, which is only limited to a given window of time from the moment the lock is acquired.
There's plenty of libraries out there that follows the above pattern for a multitude of programming languages. Let's take a look at a Node.js-based implementation by the redislock npm package:
 Should pretty self-explanatory, plus it's fairly simple to integrate within existing logic in your software.
Should pretty self-explanatory, plus it's fairly simple to integrate within existing logic in your software.
If we take even one more step forward, we can look at the nice cron-cluster npm library which integrates a similar concept using redis-leader and cronjobs all within the same lib:
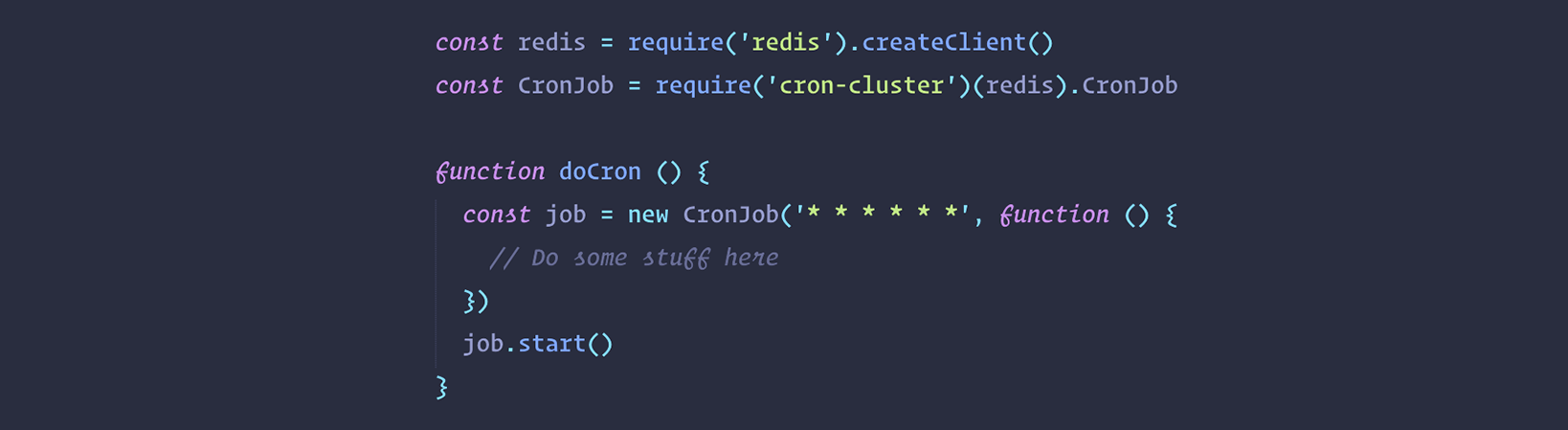 You can see how well hidden behind the scene is the logic in the last example here above. This means you can define cronjobs at application-level software in your backend without worrying about mutual exclusion and so on. We should be thankful to such good open-source packages out there!
You can see how well hidden behind the scene is the logic in the last example here above. This means you can define cronjobs at application-level software in your backend without worrying about mutual exclusion and so on. We should be thankful to such good open-source packages out there!